ADAPT
ADAPT is a Python package providing some well known domain adaptation methods.
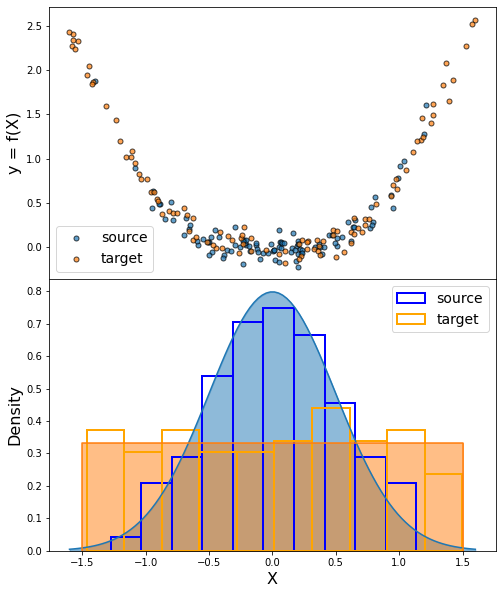
The purpose of domain adaptation (DA) methods is to handle the common issue encounter in machine learning where training and testing data are drawn according to different distributions.
In domain adaptation setting, one is aiming to learn a task with an estimator \(f\) mapping input data \(X\) into output data \(y\) called also labels. \(y\) is either a finite set of integer value (for classification tasks) or an interval of real values (for regression tasks).
Besides, in this setting, one consider, on one hand, a source domain from which a large sample of labeled data \((X_S, y_S)\) are available. And in the other hand, a target domain from which no (or only a few) labeled data \((X_T, y_T)\) are available. If no labeled target data are available, one refers to unsupervised domain adaptation. If a few labeled target data are available one refers to supervised domain adaptation also called few-shot learning.
The goal of domain adaptation is to build a good estimator \(f_T\) on the target domain by leaveraging information from the source domain. DA methods follow one of these three strategies:
The following part explains each strategy and gives lists of the implemented methods in the ADAPT package.
adapt.feature_based: Feature-Based Methods
Feature-based methods are based on the research of common features which have similar behaviour with respect to the task on source and target domain.
A new feature representation (often called encoded feature space) is built with a projecting application \(\phi\) which aims to correct the difference between source and target distributions. The task is then learned in this encoded feature space.
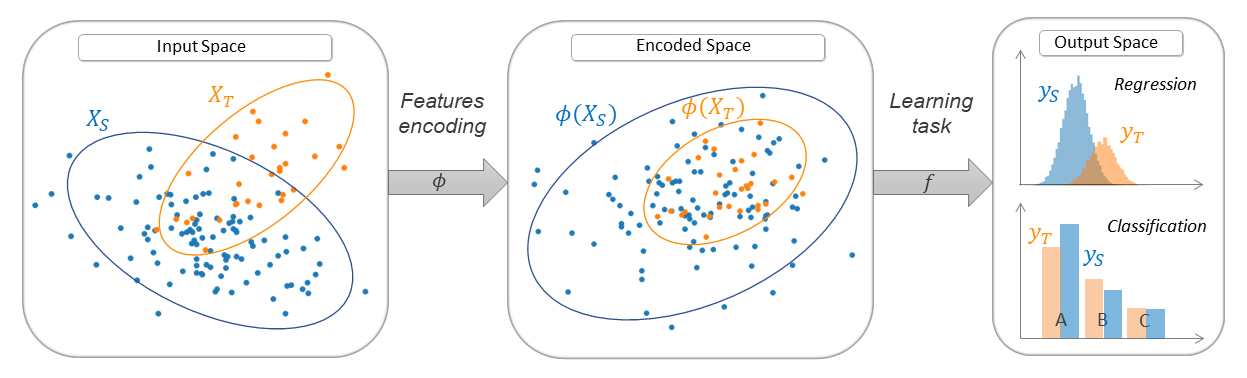
Methods
|
PRED: Feature Augmentation with SrcOnly Prediction |
|
FA: Feature Augmentation. |
|
CORAL: CORrelation ALignment |
|
SA : Subspace Alignment |
|
TCA : Transfer Component Analysis |
|
fMMD : feature Selection with MMD |
|
DeepCORAL: Deep CORrelation ALignment |
|
DANN: Discriminative Adversarial Neural Network |
|
ADDA: Adversarial Discriminative Domain Adaptation |
|
WDGRL: Wasserstein Distance Guided Representation Learning |
|
CDAN: Conditional Adversarial Domain Adaptation |
|
MCD: Maximum Classifier Discrepancy |
|
MDD: Margin Disparity Discrepancy |
|
CCSA : Classification and Contrastive Semantic Alignment |
adapt.instance_based: Instance-Based Methods
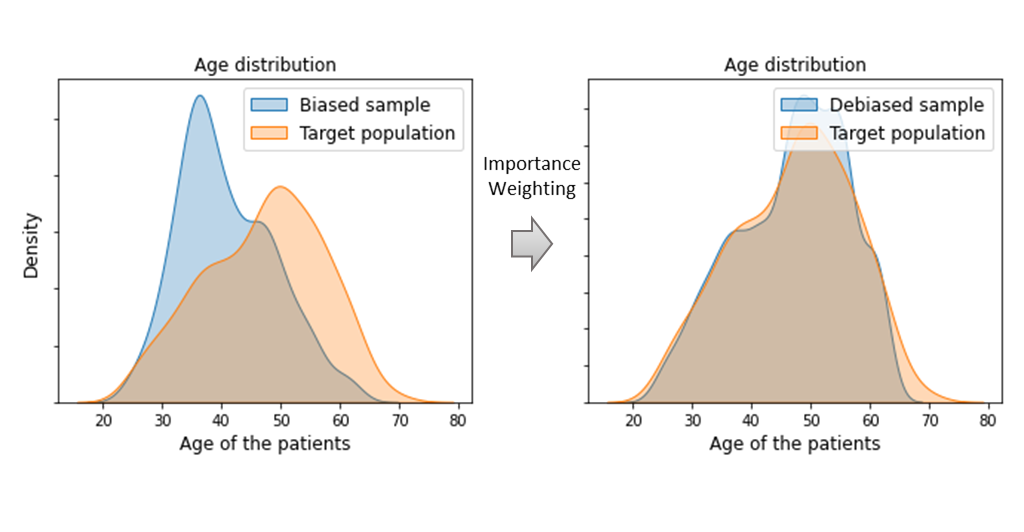
The general principle of these methods is to reweight labeled training data in order to correct the difference between source and target distributions. This reweighting consists in multiplying, during the training process, the individual loss of each training instance by a positive weight.
The reweighted training instances are then directly used to learn the task.
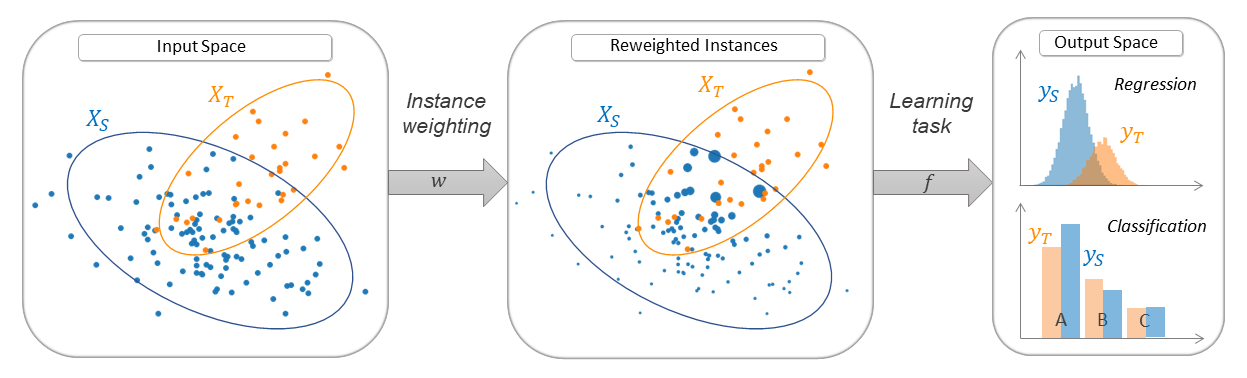
Methods
|
LDM : Linear Discrepancy Minimization |
|
KLIEP: Kullback–Leibler Importance Estimation Procedure |
|
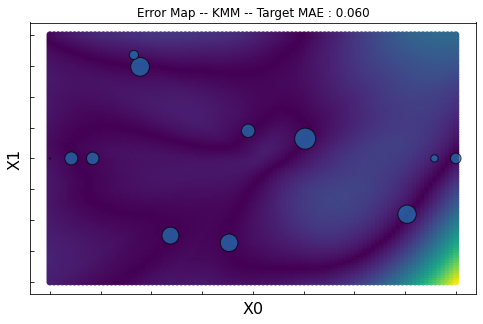
KMM: Kernel Mean Matching |
|
ULSIF: Unconstrained Least-Squares Importance Fitting |
|
RULSIF: Relative Unconstrained Least-Squares Importance Fitting |
NNW : Nearest Neighbors Weighting |
|
|
IWC: Importance Weighting Classifier |
|
IWN : Importance Weighting Network |
BW : Balanced Weighting |
|
|
Transfer AdaBoost for Classification |
|
Transfer AdaBoost for Regression |
Two Stage Transfer AdaBoost for Regression |
|
|
WANN : Weighting Adversarial Neural Network |
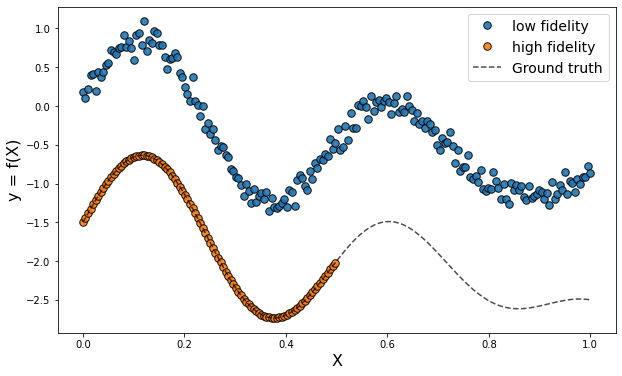
adapt.parameter_based: Parameter-Based Methods
In parameter-based methods, the parameters of one or few pre-trained models built with the source data are adapted to build a suited model for the task on the target domain.
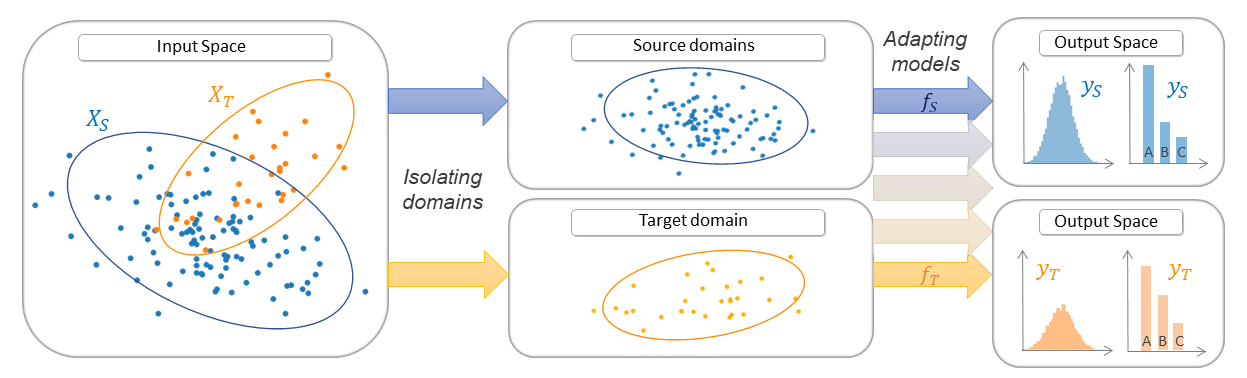
Methods
|
LinInt: Linear Interpolation between SrcOnly and TgtOnly. |
Regular Transfer with Linear Regression |
|
Regular Transfer for Linear Classification |
|
|
Regular Transfer with Neural Network |
Regular Transfer with Gaussian Process |
|
|
FineTuning : finetunes pretrained networks on target data. |
TransferTreeClassifier: Modify a source Decision tree on a target dataset. |
|
TransferForestClassifier: Modify a source Random Forest on a target dataset. |
|
TransferTreeSelector : Run several decision tree transfer algorithms on a target dataset and select the best one. |
|
TransferForestSelector : Run several decision tree transfer algorithms on a target dataset and select the best one for each tree of the random forest. |
adapt.metrics: Metrics
This module contains functions to compute adaptation metrics.
|
Make a scorer function from an adapt metric. |
|
Compute the mean absolute difference between the covariance matrixes of Xs and Xt |
|
Compute the negative J-score between Xs and Xt. |
|
Compute the linear discrepancy between Xs and Xt. |
Compute the normalized linear discrepancy between Xs and Xt. |
|
|
Compute the frechet distance between Xs and Xt. |
Compute the normalized frechet distance between Xs and Xt. |
|
|
Return 1 minus the mean square error of a classifer disciminating between Xs and Xt. |
|
Reverse validation. |
adapt.utils: Utility Functions
This module contains utility functions used in the previous modules.
|
Update Lambda trade-off |
|
Custom accuracy function which can handle probas vector in both binary and multi classification |
|
Check arrays and reshape 1D array in 2D array of shape (-1, 1). |
|
Check estimator. |
|
Check if the given network is a tensorflow Model. |
|
Return a tensorflow Model of one layer with 10 neurons and a relu activation. |
|
Return a tensorflow Model of two hidden layers with 10 neurons each and relu activations. |
|
Return a tensorflow Model of two hidden layers with 10 neurons each and relu activations. |
|
Multiply gradients with a scalar during backpropagation. |
|
Generate a classification dataset for DA. |
|
Generate a regression dataset for DA. |
|
Check sample weights. |
|
Set random seed for numpy and Tensorflow |
|
Check Fitted Estimator |
|
Check Fitted Network |