adapt.parameter_based.FineTuning
- class adapt.parameter_based.FineTuning(encoder=None, task=None, Xt=None, yt=None, training=True, pretrain=False, verbose=1, copy=True, random_state=None, **params)[source]
FineTuning : finetunes pretrained networks on target data.
A pretrained source encoder should be given. A task network, pretrained or not, should be given too.
Finetuning train both networks. The task network can be fitted first using the
pretrainparameter. The layers to train in the encoder can be set via the parametertraining.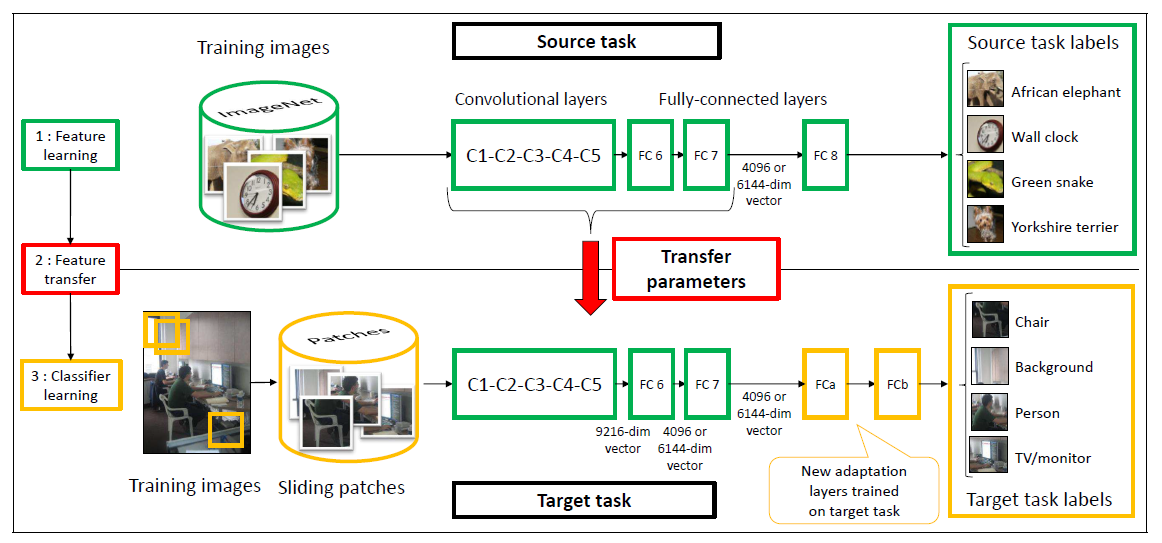
Transferring parameters of a CNN pretrained on Imagenet (source: [1])
- Parameters
- encodertensorflow Model (default=None)
Encoder netwok. If
None, a shallow network with 10 neurons and ReLU activation is used as encoder network.- tasktensorflow Model (default=None)
Task netwok. If
None, a two layers network with 10 neurons per layer and ReLU activation is used as task network.- Xtnumpy array (default=None)
Target input data.
- ytnumpy array (default=None)
Target output data.
- trainingbool or list of bool, optional (default=True)
Weither to train the
encoderor not. If a list is given, values fromtrainingare assigned successively to thetrainableattribute of theencoderlayers going from the last layer to the first one. If the length oftrainingis smaller than the length of theencoderlayers list, the last value oftrainingwill be asigned to the remaining layers.- pretrainbool (default=False)
If True, the task network is first trained alone on the outputs of the encoder.
- copyboolean (default=True)
Whether to make a copy of
estimatoror not.- verboseint (default=1)
Verbosity level.
- random_stateint (default=None)
Seed of random generator.
- paramskey, value arguments
Arguments given at the different level of the adapt object. It can be, for instance, compile or fit parameters of the estimator or kernel parameters etc… Accepted parameters can be found by calling the method
_get_legal_params(params).
- Yields
- optimizerstr or instance of tf.keras.optimizers (default=”rmsprop”)
Optimizer for the task. It should be an instance of tf.keras.optimizers as:
tf.keras.optimizers.SGD(0.001)ortf.keras.optimizers.Adam(lr=0.001, beta_1=0.5). A string can also be given as"adam". Default optimizer isrmsprop.- lossstr or instance of tf.keras.losses (default=”mse”)
Loss for the task. It should be an instance of tf.keras.losses as:
tf.keras.losses.MeanSquaredError()ortf.keras.losses.CategoricalCrossentropy(). A string can also be given as"mse"orcategorical_crossentropy. Default loss ismse.- metricslist of str or list of tf.keras.metrics.Metric instance
List of metrics to be evaluated by the model during training and testing. Typically you will use
metrics=['accuracy'].- optimizer_encstr or instance of tf.keras.optimizers
If the Adapt Model has an
encoderattribute, a specific optimizer for theencodernetwork can be given. Typically, this parameter can be used to give a smaller learning rate to the encoder. If not specified,optimizer_enc=optimizer.- optimizer_discstr or instance of tf.keras.optimizers
If the Adapt Model has a
discriminatorattribute, a specific optimizer for thediscriminatornetwork can be given. If not specified,optimizer_disc=optimizer.- kwargskey, value arguments
Any arguments of the
fitmethod from the Tensorflow Model can be given, asepochsandbatch_size. Specific arguments fromoptimizercan also be given aslearning_rateorbeta_1forAdam. This allows to performGridSearchCVfrom scikit-learn on these arguments.
References
- 1
[1] Oquab M., Bottou L., Laptev I., Sivic J. “Learning and transferring mid-level image representations using convolutional neural networks”. In CVPR, 2014.
Examples
>>> from adapt.utils import make_regression_da >>> from adapt.parameter_based import FineTuning >>> Xs, ys, Xt, yt = make_regression_da() >>> src_model = FineTuning(loss="mse", pretrain=False, random_state=0) >>> src_model.fit(Xs, ys, epochs=100, verbose=0) >>> print(src_model.score(Xt, yt)) 1/1 [==============================] - 0s 82ms/step - loss: 0.2645 0.26447802782058716 >>> tgt_model = FineTuning(encoder=src_model.encoder_, loss="mse", pretrain=True, ... pretrain__epochs=30, random_state=0) >>> tgt_model.fit(Xt[:3], yt[:3], epochs=100, verbose=0) >>> tgt_model.score(Xt, yt) 1/1 [==============================] - 0s 78ms/step - loss: 0.1114 0.11144775152206421
- Attributes
- encoder_tensorflow Model
encoder network.
- task_tensorflow Model
Network.
- history_dict
history of the losses and metrics across the epochs of the network training.
Methods
__init__([encoder, task, Xt, yt, training, ...])compile([optimizer, loss, metrics, ...])Configures the model for training.
fit([Xt, yt])Fit FineTuning.
get_params([deep])Get parameters for this estimator.
load_weights(filepath[, skip_mismatch, ...])Loads all layer weights from a saved files.
predict(x[, batch_size, verbose, steps, ...])Generates output predictions for the input samples.
predict_disc(X)Not used.
predict_task(X)Return predictions of the task on the encoded features.
pretrain_step(data)save_weights(filepath[, overwrite, ...])Saves all layer weights.
score(X, y[, sample_weight])Return the evaluation of the model on X, y.
set_params(**params)Set the parameters of this estimator.
transform(X)Return the encoded features of X.
unsupervised_score(Xs, Xt)Return unsupervised score.
- __init__(encoder=None, task=None, Xt=None, yt=None, training=True, pretrain=False, verbose=1, copy=True, random_state=None, **params)[source]
- compile(optimizer=None, loss=None, metrics=None, loss_weights=None, weighted_metrics=None, run_eagerly=None, steps_per_execution=None, **kwargs)[source]
Configures the model for training.
- Parameters
- optimizer: str or `tf.keras.optimizer` instance
Optimizer
- loss: str or `tf.keras.losses.Loss` instance
Loss function. A loss function is any callable with the signature loss = fn(y_true, y_pred), where y_true are the ground truth values, and y_pred are the model’s predictions. y_true should have shape (batch_size, d0, .. dN) (except in the case of sparse loss functions such as sparse categorical crossentropy which expects integer arrays of shape (batch_size, d0, .. dN-1)). y_pred should have shape (batch_size, d0, .. dN). The loss function should return a float tensor. If a custom Loss instance is used and reduction is set to None, return value has shape (batch_size, d0, .. dN-1) i.e. per-sample or per-timestep loss values; otherwise, it is a scalar. If the model has multiple outputs, you can use a different loss on each output by passing a dictionary or a list of losses. The loss value that will be minimized by the model will then be the sum of all individual losses, unless loss_weights is specified.
- metrics: list of str or list of `tf.keras.metrics.Metric` instance
List of metrics to be evaluated by the model during training and testing. Typically you will use metrics=[‘accuracy’]. A function is any callable with the signature result = fn(y_true, y_pred). To specify different metrics for different outputs of a multi-output model, you could also pass a dictionary, such as metrics={‘output_a’: ‘accuracy’, ‘output_b’: [‘accuracy’, ‘mse’]}. You can also pass a list to specify a metric or a list of metrics for each output, such as metrics=[[‘accuracy’], [‘accuracy’, ‘mse’]] or metrics=[‘accuracy’, [‘accuracy’, ‘mse’]]. When you pass the strings ‘accuracy’ or ‘acc’, we convert this to one of tf.keras.metrics.BinaryAccuracy, tf.keras.metrics.CategoricalAccuracy, tf.keras.metrics.SparseCategoricalAccuracy based on the loss function used and the model output shape. We do a similar conversion for the strings ‘crossentropy’ and ‘ce’ as well.
- loss_weights: List or dict of floats
Scalars to weight the loss contributions of different model outputs. The loss value that will be minimized by the model will then be the weighted sum of all individual losses, weighted by the loss_weights coefficients. If a list, it is expected to have a 1:1 mapping to the model’s outputs. If a dict, it is expected to map output names (strings) to scalar coefficients.
- weighted_metrics: list of metrics
List of metrics to be evaluated and weighted by sample_weight or class_weight during training and testing.
- run_eagerly: bool (default=False)
If True, this Model’s logic will not be wrapped in a tf.function. Recommended to leave this as None unless your Model cannot be run inside a tf.function. run_eagerly=True is not supported when using tf.distribute.experimental.ParameterServerStrategy.
- steps_per_execution: int (default=1)
The number of batches to run during each tf.function call. Running multiple batches inside a single tf.function call can greatly improve performance on TPUs or small models with a large Python overhead. At most, one full epoch will be run each execution. If a number larger than the size of the epoch is passed, the execution will be truncated to the size of the epoch. Note that if steps_per_execution is set to N, Callback.on_batch_begin and Callback.on_batch_end methods will only be called every N batches (i.e. before/after each tf.function execution).
- **kwargs: key, value arguments
Arguments supported for backwards compatibility only.
- Returns
- None: None
- fit(Xt=None, yt=None, **fit_params)[source]
Fit FineTuning.
- Parameters
- Xtnumpy array (default=None)
Target input data.
- ytnumpy array (default=None)
Target output data.
- fit_paramskey, value arguments
Arguments given to the fit method of the model (epochs, batch_size, callbacks…).
- Returns
- selfreturns an instance of self
- get_params(deep=True)[source]
Get parameters for this estimator.
- Parameters
- deepbool, default=True
Not used, here for scikit-learn compatibility.
- Returns
- paramsdict
Parameter names mapped to their values.
- load_weights(filepath, skip_mismatch=False, by_name=False, options=None)[source]
Loads all layer weights from a saved files.
The saved file could be a SavedModel file, a .keras file (v3 saving format), or a file created via model.save_weights().
By default, weights are loaded based on the network’s topology. This means the architecture should be the same as when the weights were saved. Note that layers that don’t have weights are not taken into account in the topological ordering, so adding or removing layers is fine as long as they don’t have weights.
Partial weight loading
If you have modified your model, for instance by adding a new layer (with weights) or by changing the shape of the weights of a layer, you can choose to ignore errors and continue loading by setting skip_mismatch=True. In this case any layer with mismatching weights will be skipped. A warning will be displayed for each skipped layer.
Weight loading by name
If your weights are saved as a .h5 file created via model.save_weights(), you can use the argument by_name=True.
In this case, weights are loaded into layers only if they share the same name. This is useful for fine-tuning or transfer-learning models where some of the layers have changed.
Note that only topological loading (by_name=False) is supported when loading weights from the .keras v3 format or from the TensorFlow SavedModel format.
- Args:
- filepath: String, path to the weights file to load. For weight files
in TensorFlow format, this is the file prefix (the same as was passed to save_weights()). This can also be a path to a SavedModel or a .keras file (v3 saving format) saved via model.save().
- skip_mismatch: Boolean, whether to skip loading of layers where
there is a mismatch in the number of weights, or a mismatch in the shape of the weights.
- by_name: Boolean, whether to load weights by name or by topological
order. Only topological loading is supported for weight files in the .keras v3 format or in the TensorFlow SavedModel format.
- options: Optional tf.train.CheckpointOptions object that specifies
options for loading weights (only valid for a SavedModel file).
- predict(x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)[source]
Generates output predictions for the input samples.
Computation is done in batches. This method is designed for performance in large scale inputs. For small amount of inputs that fit in one batch, directly using __call__() is recommended for faster execution, e.g., model(x), or model(x, training=False) if you have layers such as tf.keras.layers.BatchNormalization that behaves differently during inference. Also, note the fact that test loss is not affected by regularization layers like noise and dropout.
- Parameters
- x: array
Input samples.
- batch_size: int (default=`None`)
Number of samples per batch. If unspecified, batch_size will default to 32. Do not specify the batch_size if your data is in the form of dataset, generators, or keras.utils.Sequence instances (since they generate batches).
- verbose: int (default=0)
Verbosity mode, 0 or 1.
- steps: int (default=None)
Total number of steps (batches of samples) before declaring the prediction round finished. Ignored with the default value of None. If x is a tf.data dataset and steps is None, predict() will run until the input dataset is exhausted.
- callbacks: List of `keras.callbacks.Callback` instances.
List of callbacks to apply during prediction. See [callbacks](/api_docs/python/tf/keras/callbacks).
- max_queue_size: int (default=10)
Used for generator or keras.utils.Sequence input only. Maximum size for the generator queue. If unspecified, max_queue_size will default to 10.
- workers: int (default=1)
Used for generator or keras.utils.Sequence input only. Maximum number of processes to spin up when using process-based threading. If unspecified, workers will default to 1.
- use_multiprocessing: bool (default=False)
Used for generator or keras.utils.Sequence input only. If True, use process-based threading. If unspecified, use_multiprocessing will default to False. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can’t be passed easily to children processes.
- Returns
- y_predarray
Numpy array(s) of predictions.
- predict_task(X)[source]
Return predictions of the task on the encoded features.
- Parameters
- Xarray
input data
- Returns
- y_taskarray
predictions of task network
- save_weights(filepath, overwrite=True, save_format=None, options=None)[source]
Saves all layer weights.
Either saves in HDF5 or in TensorFlow format based on the save_format argument.
- When saving in HDF5 format, the weight file has:
- layer_names (attribute), a list of strings
(ordered names of model layers).
- For every layer, a group named layer.name
- For every such layer group, a group attribute weight_names,
a list of strings (ordered names of weights tensor of the layer).
- For every weight in the layer, a dataset
storing the weight value, named after the weight tensor.
When saving in TensorFlow format, all objects referenced by the network are saved in the same format as tf.train.Checkpoint, including any Layer instances or Optimizer instances assigned to object attributes. For networks constructed from inputs and outputs using tf.keras.Model(inputs, outputs), Layer instances used by the network are tracked/saved automatically. For user-defined classes which inherit from tf.keras.Model, Layer instances must be assigned to object attributes, typically in the constructor. See the documentation of tf.train.Checkpoint and tf.keras.Model for details.
While the formats are the same, do not mix save_weights and tf.train.Checkpoint. Checkpoints saved by Model.save_weights should be loaded using Model.load_weights. Checkpoints saved using tf.train.Checkpoint.save should be restored using the corresponding tf.train.Checkpoint.restore. Prefer tf.train.Checkpoint over save_weights for training checkpoints.
The TensorFlow format matches objects and variables by starting at a root object, self for save_weights, and greedily matching attribute names. For Model.save this is the Model, and for Checkpoint.save this is the Checkpoint even if the Checkpoint has a model attached. This means saving a tf.keras.Model using save_weights and loading into a tf.train.Checkpoint with a Model attached (or vice versa) will not match the Model’s variables. See the [guide to training checkpoints]( https://www.tensorflow.org/guide/checkpoint) for details on the TensorFlow format.
- Args:
- filepath: String or PathLike, path to the file to save the weights
to. When saving in TensorFlow format, this is the prefix used for checkpoint files (multiple files are generated). Note that the ‘.h5’ suffix causes weights to be saved in HDF5 format.
- overwrite: Whether to silently overwrite any existing file at the
target location, or provide the user with a manual prompt.
- save_format: Either ‘tf’ or ‘h5’. A filepath ending in ‘.h5’ or
‘.keras’ will default to HDF5 if save_format is None. Otherwise, None becomes ‘tf’. Defaults to None.
- options: Optional tf.train.CheckpointOptions object that specifies
options for saving weights.
- Raises:
- ImportError: If h5py is not available when attempting to save in
HDF5 format.
- score(X, y, sample_weight=None)[source]
Return the evaluation of the model on X, y.
Call evaluate on tensorflow Model.
- Parameters
- Xarray
input data
- yarray
output data
- sample_weightarray (default=None)
Sample weights
- Returns
- scorefloat
Score.
- set_params(**params)[source]
Set the parameters of this estimator.
- Parameters
- **paramsdict
Estimator parameters.
- Returns
- selfestimator instance
Estimator instance.